Section 11 Abundance vs. detections
In this script, we run correlations and regressions between abundance (as estimated from point count data) and detections (as estimated from acoustic data).
11.1 Install necessary libraries
library(tidyverse)
library(dplyr)
library(stringr)
library(vegan)
library(ggplot2)
library(scico)
library(data.table)
library(extrafont)
library(ggstatsplot)
library(ggside)
library(MASS)
library(scales)
library(rr2)
library(ggnewscale)
library(ggpubr)
library(gridtext)
library(broom)
# Source any custom/other internal functions necessary for analysis
source("code/01_internal-functions.R")11.3 Estimate abundance for point count data and detections for acoustic data
Here, we make a distinction before running correlative analyses that abundance corresponds to the total number of individuals of a species detected across visits to a site and can only be calculated for point count data. In the acoustic dataset, individuals are not seen and a measure of detections (estimated as the total number of times as species was heard across ~576 10-s clips). Here 576 clips correspond to the total amount of acoustic data - 96 min (576 10-s clips) of data = 16-min of data for every visit).
# point-count data
# estimate total abundance across all species for each site
abundance <- datSubset %>%
filter(data_type == "point_count") %>%
group_by(site_id, restoration_type, scientific_name,
common_name, eBird_codes) %>%
summarise(abundance_pc = sum(number)) %>%
ungroup()
# estimate total number of detections across the acoustic data
# note: we cannot call this abundance as it refers to the total number of vocalizations across all sites
detections <- datSubset %>%
filter(data_type == "acoustic_data") %>%
group_by(site_id, restoration_type, scientific_name,
common_name, eBird_codes) %>%
summarise(detections_aru = sum(number)) %>%
ungroup()11.4 Correlations between abundance and detections
# create a single dataframe
data <- full_join(abundance, detections)%>%
replace_na(list(abundance_pc = 0, detections_aru = 0))
# reordering factors for plotting
data$restoration_type <- factor(data$restoration_type, levels = c("BM", "AR", "NR"))
# visualization
fig_abund_detec <- grouped_ggscatterstats(
data = data,
x = detections_aru,
y = abundance_pc,
grouping.var = restoration_type,
type = "r",
plotgrid.args = list(nrow = 3, ncol = 1),
ggplot.component = list(theme(text = element_text(family = "Century Gothic", size = 15, face = "bold"),plot.title = element_text(family = "Century Gothic",
size = 18, face = "bold"),
plot.subtitle = element_text(family = "Century Gothic",
size = 15, face = "bold",color="#1b2838"),
axis.title = element_text(family = "Century Gothic",
size = 15, face = "bold"))))
ggsave(fig_abund_detec, filename = "figs/fig_abundance_vs_detections_correlations.png", width = 14, height = 16, device = png(), units = "in", dpi = 300)
dev.off() 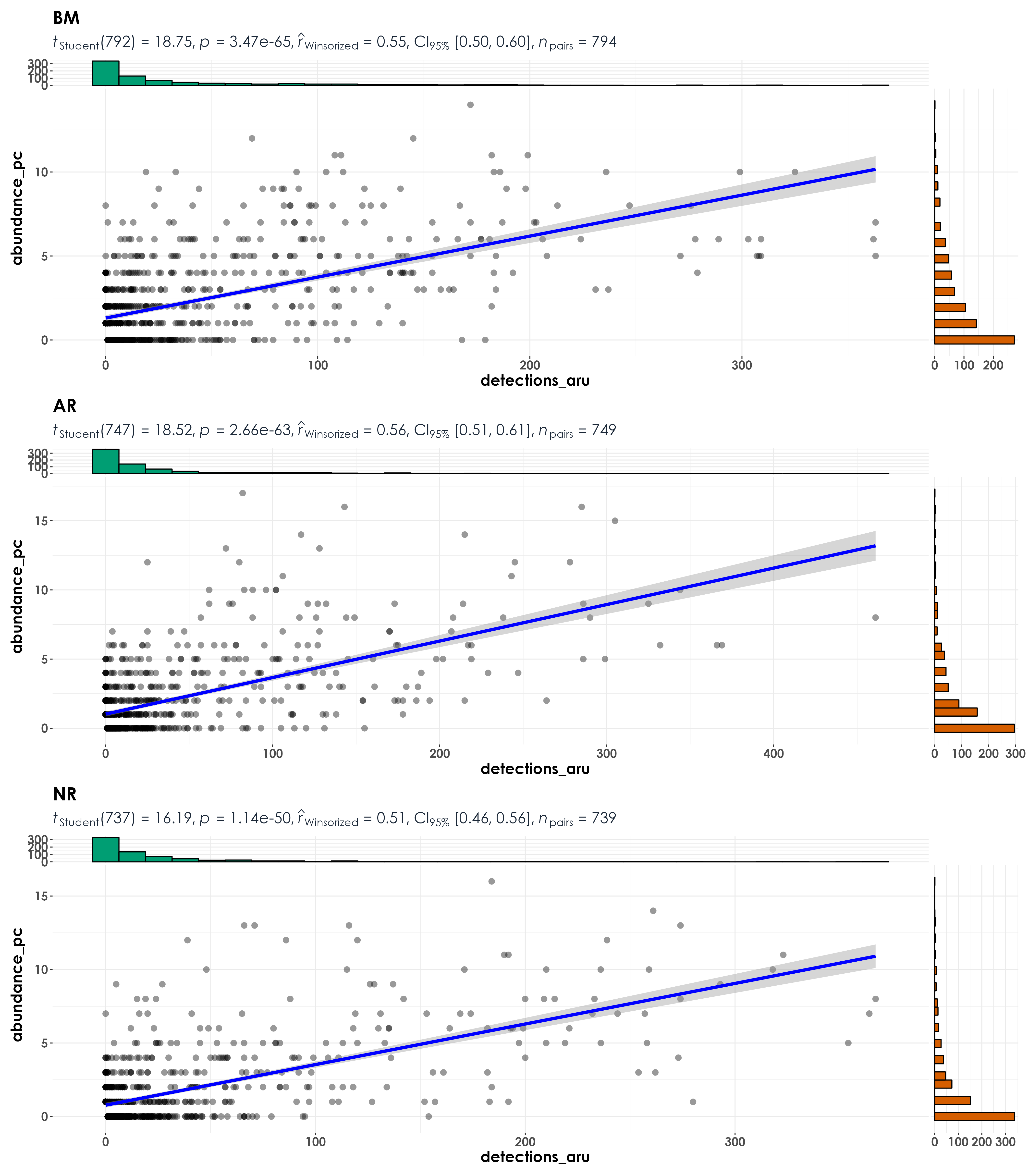
11.5 Combine site-level data to test for correlations between abundance and detections for each species (at the level of the treatment type)
Here, each dot in the visualization refers to a particular species and the only difference between this analysis and previous one is that the site-level variation is compressed/lost and the visualization/correlative analyses are being carried out across species and treatment types.
# grouping point count data at the level of the treatment type
abundance_group <- data %>%
group_by(restoration_type, scientific_name,
common_name, eBird_codes) %>%
summarise(abundance_pc = sum(abundance_pc)) %>%
ungroup()
# grouping acoustic data at the level of the treatment type
detections_group <- data %>%
group_by(restoration_type, scientific_name,
common_name, eBird_codes) %>%
summarise(detections_aru = sum(detections_aru)) %>%
ungroup()
# create a single dataframe
# subset data to get a minimum abundance of ten and a minimum number of acoustic detections of ten
data_group <- full_join(abundance_group, detections_group) %>%
filter(abundance_pc >=10 & detections_aru >= 10)
# reordering factors for plotting
data_group$restoration_type <- factor(data_group$restoration_type, levels = c("BM", "AR", "NR"))
# visualization
fig_abund_detec_group <- grouped_ggscatterstats(
data = data_group,
x = detections_aru,
y = abundance_pc,
grouping.var = restoration_type,
type = "r",
label.var = scientific_name,
label.expression = detections_aru > 500,
point.label.args = list(alpha = 0.7, size = 4, color = "grey50"),
plotgrid.args = list(nrow = 3, ncol = 1),
ggplot.component = list(theme(text = element_text(family = "Century Gothic", size = 15, face = "bold"),plot.title = element_text(family = "Century Gothic",
size = 18, face = "bold"),
plot.subtitle = element_text(family = "Century Gothic",
size = 15, face = "bold",color="#1b2838"),
axis.title = element_text(family = "Century Gothic",
size = 15, face = "bold"))))
ggsave(fig_abund_detec_group, filename = "figs/fig_abundance_vs_detections_treatmentLevel_correlations.png", width = 14, height = 16, device = png(), units = "in", dpi = 300)
dev.off() 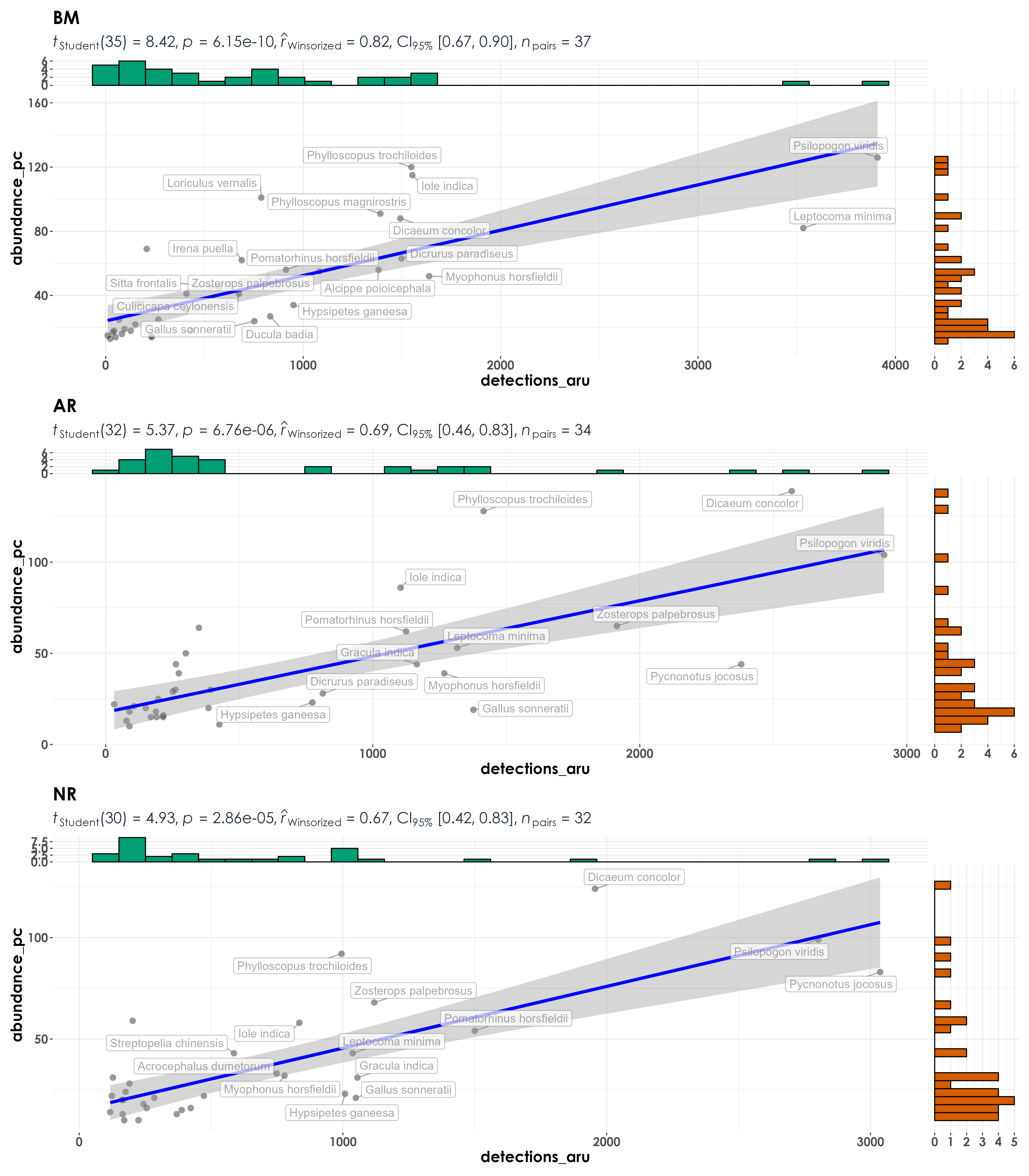
11.6 Rerun analysis at the level of each species (across all sites and treatments combined)
Essentially a single graph that plots all the data.
# grouping point count data
abundance_group <- data %>%
group_by(scientific_name,
common_name, eBird_codes) %>%
summarise(abundance_pc = sum(abundance_pc)) %>%
ungroup()
# grouping acoustic data at the level of the treatment type
detections_group <- data %>%
group_by(scientific_name,
common_name, eBird_codes) %>%
summarise(detections_aru = sum(detections_aru)) %>%
ungroup()
# create a single dataframe
# subset data to get a minimum abundance of ten and a minimum number of acoustic detections of ten
data_group <- full_join(abundance_group, detections_group) %>%
filter(abundance_pc >=10 & detections_aru >= 10)
# visualization
fig_abund_detec_community <- ggscatterstats(
data = data_group,
x = abundance_pc,
y = detections_aru,
type = "r",
label.var = common_name,
label.expression = detections_aru > 4000,
point.label.args = list(alpha = 0.7, size = 4, color = "grey50"),
plotgrid.args = list(nrow = 3, ncol = 1),
ggplot.component = list(theme(text = element_text(family = "Century Gothic", size = 15, face = "bold"),plot.title = element_text(family = "Century Gothic",
size = 18, face = "bold"),
plot.subtitle = element_text(family = "Century Gothic",
size = 15, face = "bold",color="#1b2838"),
axis.title = element_text(family = "Century Gothic",
size = 15, face = "bold"))))
ggsave(fig_abund_detec_community, filename = "figs/fig_abundance_vs_detections_communityLevel_correlations.png", width = 14, height = 16, device = png(), units = "in", dpi = 300)
dev.off() 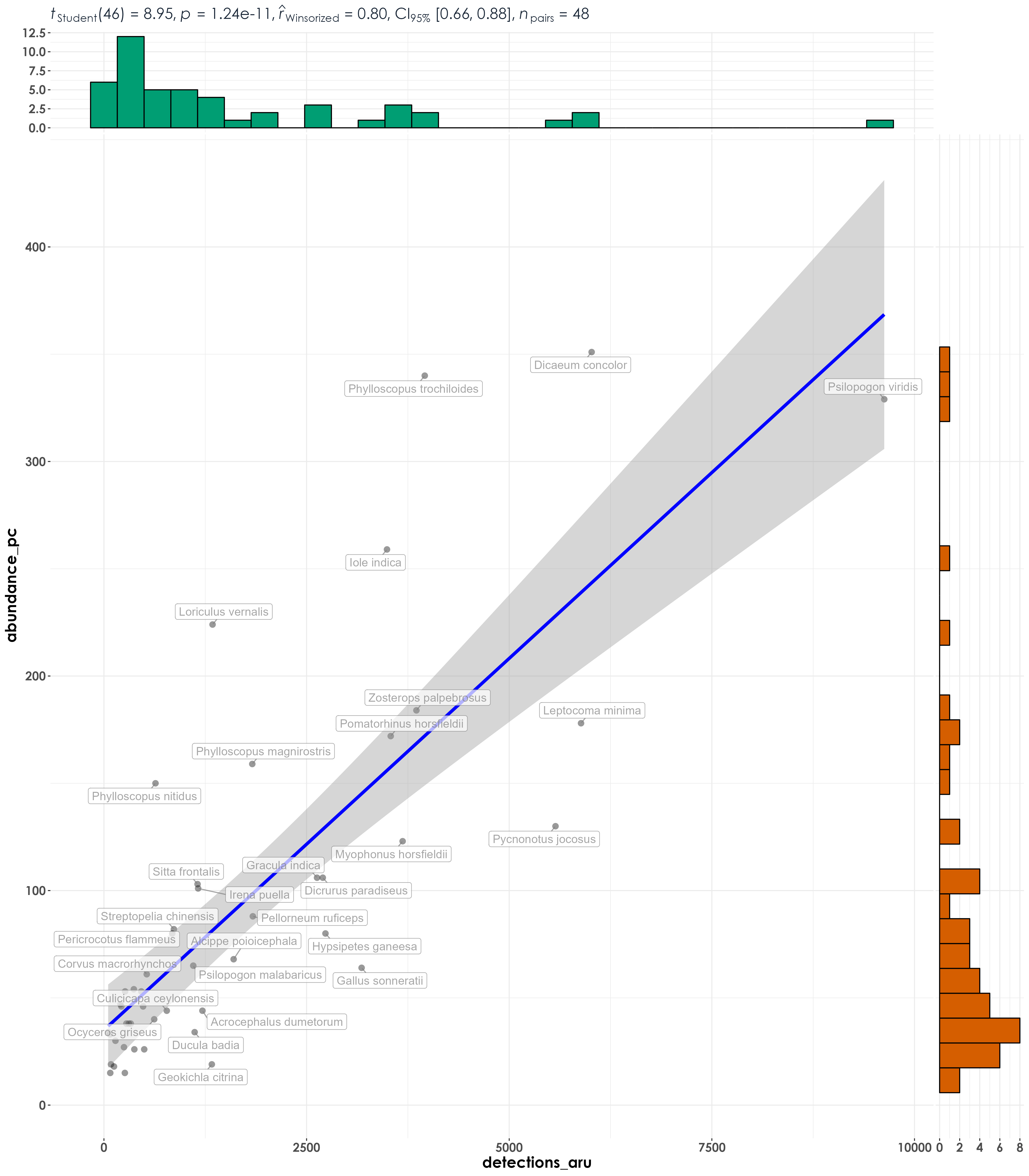
11.7 Species-specific plots of correlations between abundance and detections
For this analysis, we will not be grouping data by treatment types for plot as we have insufficient data if we divided it up. In addition, we will remove species that were detected in only or the other method (point count or acoustic surveys). Further, we only keep species that had a minimum abundance of 10 and a minimum number of acoustic detections of 10.
# identifying species that need to be kept
# only those species that have a minimum abundance value of 10 and minimum detection value of 10
spp_subset <- data %>%
group_by(scientific_name) %>%
summarise(abundance_pc = sum(abundance_pc), detections_aru = sum(detections_aru)) %>%
ungroup() %>%
filter(abundance_pc >=10 & detections_aru >= 10)
# subset data
dat_subset <- data %>%
filter(scientific_name %in% spp_subset$scientific_name)
# visualization
plots <- list()
metadata <- data.frame()
for(i in 1:length(unique(dat_subset$scientific_name))){
# extract species scientific name
a <- unique(dat_subset$scientific_name)[i]
# subset data for plotting
for_plot <- dat_subset[dat_subset$scientific_name==a,]
# create plots
plots[[i]] <- ggscatterstats(
data = for_plot,
x = detections_aru,
y = abundance_pc,
type = "r",
title = a,
ggplot.component = list(theme(text = element_text(family = "Century Gothic", size = 15, face = "bold"),plot.title = element_text(family = "Century Gothic",size = 18, face = "bold"),
plot.subtitle = element_text(family = "Century Gothic",
size = 15, face = "bold",color="#1b2838"),
axis.title = element_text(family = "Century Gothic",
size = 15, face = "bold"))))
# write the metadata to a dataframe for later analysis
# extracting information using a pre-existing function
stat <- extract_stats(plots[[i]])$subtitle_data
stat$scientific_name <- a
# add it to the above empty metadata dataframe
metadata <- rbind(metadata, stat)
}
# plot and save as a single pdf
cairo_pdf(
filename = "figs/abundance-detections-by-species-correlations.pdf",
width = 13, height = 12,
onefile = TRUE
)
plots
dev.off()
# write the metadata to a .csv
write.csv(metadata[,-14], # removing the expression column
"results/correlationScores-abundance-detections.csv",
row.names = F)Running the abundance-detections correlations analysis essentially suggests that at the community level/when species are pooled across sites - there seems to be a high Pearson’s correlation value between abundance and detections (when site-level variation is include, this ranges between 0.51 to 0.55, but when site-level variation is compressed/lost/pooled across treatments, this value ranges between 0.85 to 0.87).
However, when we break this result down and examine it for each species by species, we notice that the above result varies by species. At the species level, we considered a total of 48 species for this exercise. The list of 48 species only includes those that had a minimum abundance value of 10 and a minimum number of acoustic detections of 10.
We observed that ~15 species showed a positive r of >0.4, ~20 species showed a positive r of >0.3.Nine species showed a very small positive r value between 0 and 0.2. The species that showed the highest positive r values include Pycnonotus jocosus (0.85), Hypsipetes ganeesa (0.67) and Leptocoma minima (0.66).
Five species had a negative r value between 0 and -0.2. Seven species had a negative r value that ranged between -0.2 and -0.51. The three species showing a very high negative r value are Dicrurus aeneus (-0.51), Muscicapa muttui(-0.46), and Ficedula ruficauda (-0.45).
11.8 Regressions between abundance and detections
While it is relevant to examine correlations between abundance (as estimated from point count data) and detections (as estimated from acoustic data), we will run robust regressions to ask one predicts the other.
## We use the dat_subset dataframe moving forward, as it contains the subset of species with a minimum of 10 abundance values and 10 acoustic detections across sites and visits
## I am borrowing code from Mikula et al. 2020 below
## The data and scripts from their manuscript can be found here:
## https://osf.io/fa9ky/
dat_subset <- setDT(dat_subset)
# extract t-value
dat_subset[, t_value := summary(lm(detections_aru ~ abundance_pc))$coefficients[6], by = scientific_name]
# extract slope
dat_subset[, slope := lm(detections_aru ~ abundance_pc)%>% coef()%>% nth(2), by = scientific_name]
# extract pearson's correlation
dat_subset[, pearson := cor(detections_aru, abundance_pc), by = scientific_name]
# extract adjusted r squared
dat_subset[, r_sq := summary(lm(detections_aru ~ abundance_pc))$adj.r.squared, by = scientific_name]
# create a column with the direction of the slope (whether it is positive or negative), which can be referred to later while plotting
dat_subset[, slope_dir := ifelse(slope >0, '+', '-')]
paste("Positive regressions:",length(unique(dat_subset$scientific_name[dat_subset$slope_dir %in% c('+')])))
# 39 species had a positive regression/slope value
## visualization
fig_abund_detec_reg <- ggplot(dat_subset, aes(y = detections_aru,
x = abundance_pc)) +
geom_point(color = "#9CC3D5",size = 1.2) +
geom_smooth(data = dat_subset, aes(group = scientific_name,
color = slope_dir),
method = 'lm', se = FALSE,
linewidth = 0.7) +
scale_color_manual(values=c("#1B9E77", "#D95F02")) +
labs(y="\nDetections (from acoustic data)",
x="Abundance (from point count data)\n") +
theme_bw() +
annotate("text", x=13, y=400,
label= "Slope:", col = "grey30", size = 12) +
annotate("text", x=16, y=400,
label= "+", col = "#D95F02", size = 12) +
annotate("text", x = 18, y=400,
label = "-", col = "#1B9E77", size = 12)+
theme(text = element_text(family = "Century Gothic", size = 18, face = "bold"),plot.title = element_text(family = "Century Gothic",
size = 18, face = "bold"),
plot.subtitle = element_text(family = "Century Gothic",
size = 15, face = "bold",color="#1b2838"),
axis.title = element_text(family = "Century Gothic",
size = 18, face = "bold"),
legend.position = "none")
ggsave(fig_abund_detec_reg, filename = "figs/fig_abundance_vs_detections_regressions_allSpecies.png", width = 14, height = 16, device = png(), units = "in", dpi = 300)
dev.off()
# extract the slope, t_value, pearson correlation and the adjusted r square
lm_output <- dat_subset %>%
dplyr::select(scientific_name, t_value, slope, pearson, slope_dir,r_sq) %>% distinct()
# write the values to file
write.csv(lm_output, "results/abundance-detections-regressions.csv",
row.names = F)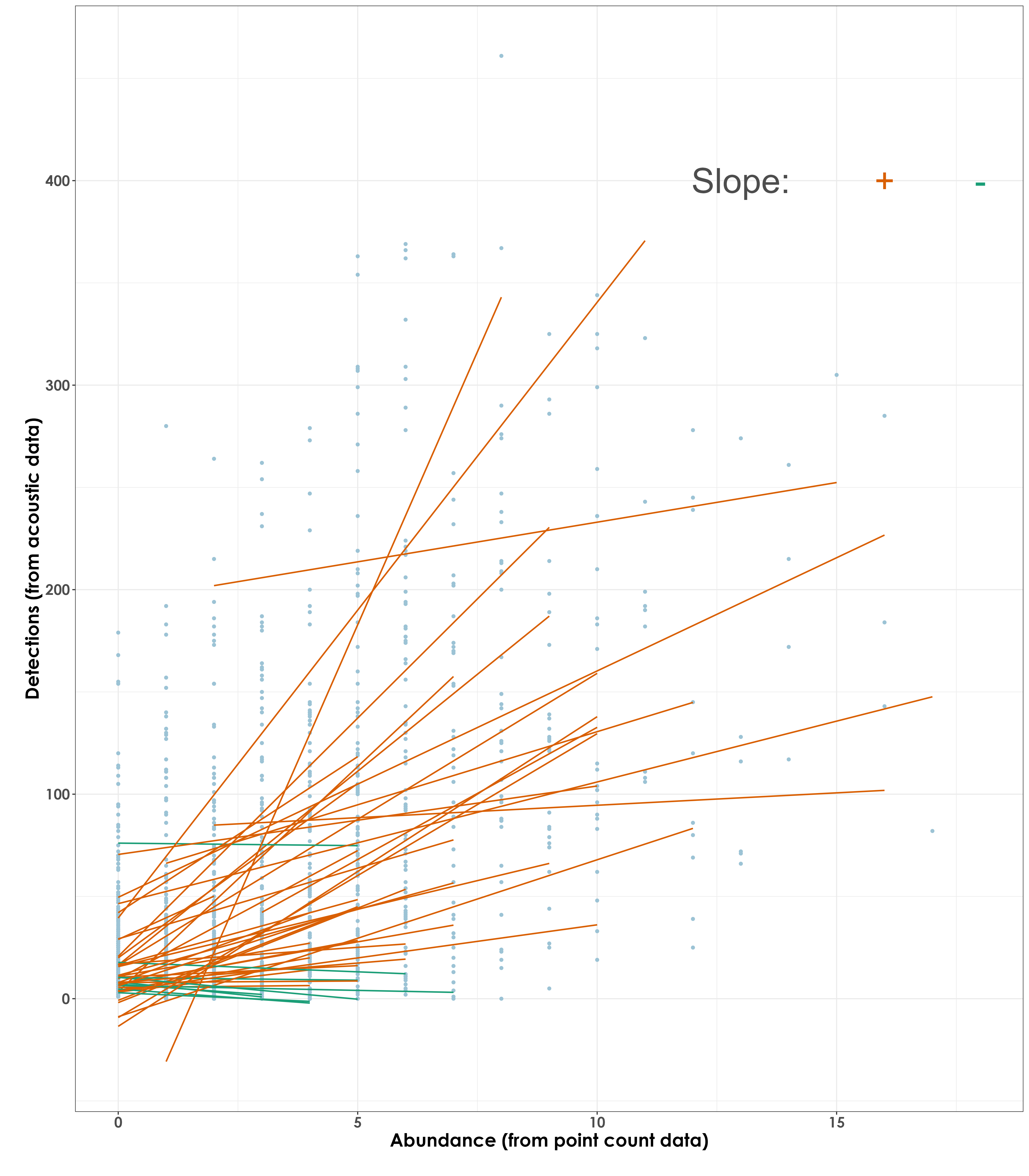
11.9 Plotting species-specific regression plots
# visualization
plots <- list()
for(i in 1:length(unique(dat_subset$common_name))){
# extract species scientific name
a <- unique(dat_subset$common_name)[37]
# subset data for plotting
for_plot <- dat_subset[dat_subset$common_name==a,]
# create plots
plots[[i]]
plot <- ggplot(for_plot, aes(y = detections_aru,
x = abundance_pc)) +
geom_point(color = "#9CC3D5",size = 1.2) +
geom_smooth(aes(color = "#D95F02"),
method = 'lm', se = TRUE,
linewidth = 0.7) +
labs(title = paste0(a," ","r_sq = ", signif(for_plot$r_sq, digits = 2), " ", paste0("slope = ",signif(for_plot$slope, digits = 4))),
y="\nDetections (from acoustic data)",
x="Abundance (from point count data)\n") +
theme_bw() +
theme(text = element_text(family = "Century Gothic", size = 18, face = "bold"),plot.title = element_text(family = "Century Gothic",
size = 18, face = "bold"),
plot.subtitle = element_text(family = "Century Gothic",
size = 15, face = "bold",color="#1b2838"),
axis.title = element_text(family = "Century Gothic",
size = 18, face = "bold"),
legend.position = "none")
}
ggsave(plot, filename = "figs/fig_lbcr.svg", width = 9, height = 9, device = svg(), units = "in", dpi = 300)
dev.off()
# plot and save as a single pdf
cairo_pdf(
filename = "figs/abundance-detections-by-species-regressions.pdf",
width = 13, height = 12,
onefile = TRUE
)
plots
dev.off() 11.10 Community-level regressions
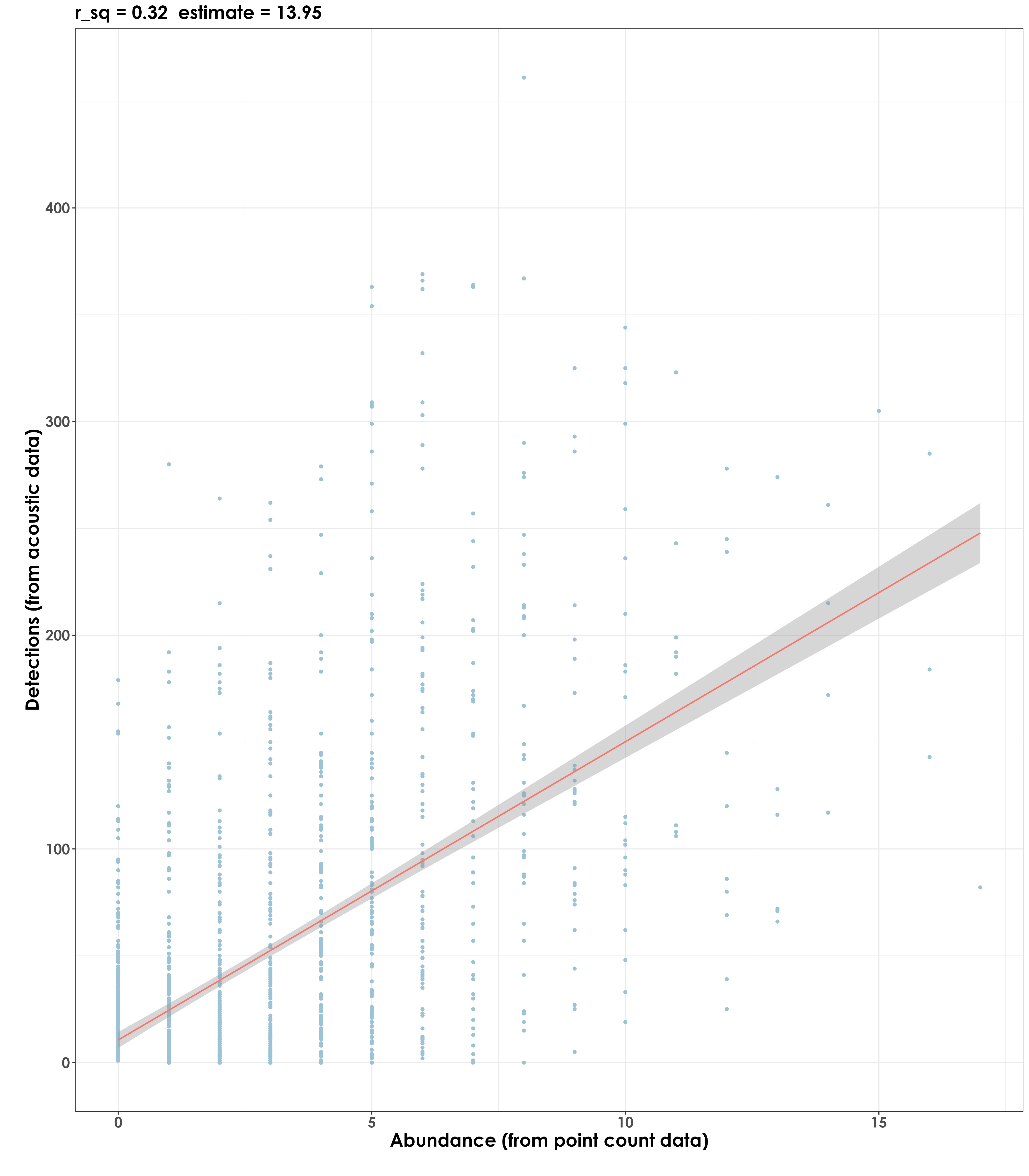
In this visualization, we essentially plot overall data of acoustic detections against abundance (from point count data)
comm_reg <- lm(detections_aru ~ abundance_pc, data=dat_subset)
summary(comm_reg)
# Call:
# lm(formula = detections_aru ~ abundance_pc, data = dat_subset)
# Residuals:
# Min 1Q Median 3Q Max
# -165.86 -29.50 -9.58 14.47 338.76
# Coefficients:
# Estimate Std. Error t value Pr(>|t|)
# (Intercept) 10.5842 1.9015 5.566 3.03e-08 ***
# abundance_pc 13.9575 0.4883 28.582 < 2e-16 ***
# Residual standard error: 56.87 on 1670 degrees of freedom
# Multiple R-squared: 0.3285, Adjusted R-squared: 0.3281
# F-statistic: 816.9 on 1 and 1670 DF, p-value: < 2.2e-16
# visualization
fig_abund_detec_comm_reg <- ggplot(dat_subset, aes(y = detections_aru,x = abundance_pc)) +
geom_point(color = "#9CC3D5",size = 1.2) +
geom_smooth(aes(color = "#D95F02"),
method = 'lm', se = TRUE,
linewidth = 0.7) +
labs(title = paste0("r_sq = 0.32", " ", paste0("estimate = 13.95")),
y="\nDetections (from acoustic data)",
x="Abundance (from point count data)\n") +
theme_bw() +
theme(text = element_text(family = "Century Gothic", size = 18, face = "bold"),plot.title = element_text(family = "Century Gothic",
size = 18, face = "bold"),
plot.subtitle = element_text(family = "Century Gothic",
size = 15, face = "bold",color="#1b2838"),
axis.title = element_text(family = "Century Gothic",
size = 18, face = "bold"),
legend.position = "none")
ggsave(fig_abund_detec_comm_reg, filename = "figs/fig_abundance_vs_detections_regressions_communityLevel.png", width = 14, height = 16, device = png(), units = "in", dpi = 300)
dev.off()